

|
|
| ISO/IEC 2022 |
| 辞書:通信用語の基礎知識 通信技術文字符号編 (CTCHRE) |
| 読み:アイエスオウ-アイイースィー-にーまるにーにー |
| 外語:ISO/IEC 2022 |
| 品詞:名詞 |
複数の言語文字(文字集合)を切り替えて利用するための符号拡張方法の一つ。
|
|
| 概要 |
| 用途 |
ASCIIの上位互換で、多種ある文字コードを任意に切り替えて使う符号化法を規定する。
7ビットだけで文字を表現する「7ビット符号」と、8ビットを使って文字を表現する「8ビット符号」がある。
7ビット符号は、32個または33個の制御文字基本集合の領域(C0)、および94個または96個の図形文字集合の領域(CL領域)を持つ。
8ビット符号はこれに、32個または33個の制御文字補助集合の領域(C1)、および94個または96個の図形文字集合の領域(CR領域)を追加する。
| 複雑 |
当初はシンプルな仕様であったが、この策定時期に日本語のJIS X 0208などが重なったこともあり、これらの仕様を混ぜるに従って奇々怪々な仕様へと変貌を遂げた。
こうして現在に至ったISO/IEC 2022の仕様は大変複雑怪奇であり、仕様書をくまなく読まないと全貌が掴めないものになっている。
| 沿革 |
| メカニズム |
| 基本 |
7ビットだけ使うものと、8ビット全てを使うものとがある。
7ビット符号は、32個の制御文字基本集合の領域(C0)、および94個または96個の図形文字集合の領域(CL領域)を持つ。
8ビット符号はこれに、32個の制御文字補助集合の領域(C1)、および94個または96個の図形文字集合の領域(CR領域)を追加する。
| 領域の構成 |
ASCIIとの互換性を維持しながら拡張するため、ASCIIの7ビットコードを拡張した形式を取る。
8ビットある領域は4つの領域に分けられ、次のようにする。
制御文字はCL/CR、図形文字はGL/GRである。
制御文字は、CLは常にバッファーC0、CRは常にバッファーC1に固定されており、変更できない。
図形文字は、4つのバッファー(G0、G1、G2、G3)があり、それぞれに任意の文字集合を指示(designate)あるいは割り当て(assign)ができ、割り当てられたバッファーは上のGLまたはGRに呼び出す(invoke)ことで利用出来る。
初期状態ではG0がGLに、G1がGRに呼び出されている。
| 具体的なメカニズム |
まず、いくつかの文字集合表の文字を混在して使うためには、文字集合表を適時切り替えて使う必要がある。
そのためには、これからどの文字集合表を使うかを指定しなければならないが、これは一般的に二段構えのしくみを取っている。
バッファーに符号を指示した後は、そのバッファーをGLまたはGRに割り当てる必要がある。これらは全て、エスケープシーケンスで行なわれる。
この符号列は、エスケープで始まり、中間文字を挟み、最後は終端文字で終わる。つまり、ESC<0個以上の中間文字><終端文字>となる。
中間文字は、2/0〜2/15の範囲とされ、必要に応じて挿入される。
終端文字は俗にFや<F>や(F)と書かれ、範囲は3/0〜7/15とされている。そのうち3/0〜3/15は情報交換当事者間の合意がある場合にのみ使えるプライベート文字集合用、4/0〜7/15はEcma Internationalにより割り当てが行なわれる符号である。
但し、ASCIIとの互換性を意識した関係から7/14〜7/15は使用せずに保留されている。
| 7ビット符号の利用法 |
| 構造 |
まず、いくつかの文字集合表の文字を混在して使うためには、文字集合表を適時切り替えて使う必要がある。そのためには、これからどの文字集合表を使うかを指定しなければならないが、これは一般的に二段構えのしくみを取っている。
7ビット符号 図解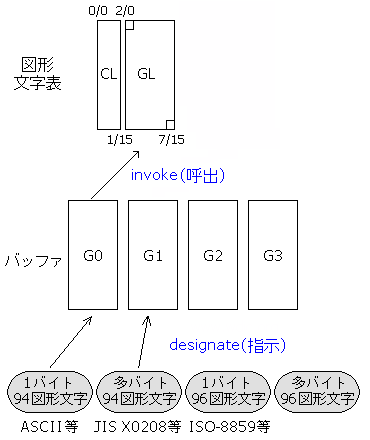
| 使う文字表とバッファー |
7ビット符号ではCLおよびGLのみを使う。つまり左だけしか使わない。
CLは常にC0であり変更できないため、CL=C0である。0/0〜1/31の32個の領域には、常に制御文字基本集合の領域(C0)が割り当てられている。
図形文字のバッファーはG0〜G3まで4つ用意され、それぞれ任意の文字集合表を割り当てておくことができる。一度に利用できるのはそのうちの一つである。
文字集合表は二種類ある。
94図形文字集合では2/0と7/15はそれぞれ空白とDEL(削除の制御文字)として固定的に使用される。
また96図形文字集合はGR領域(後述)に限定されるためバッファーG0にマッピングすることはできない。つまり7ビット符号で利用するためには、後述するLocking Shiftなどの手法が必要である。
| 7ビット実例 |
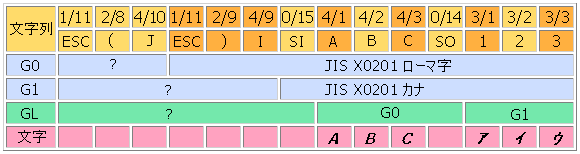
例えば、JIS X 0201ローマ字を指示する終端文字は4/10である。実際にはESC 2/8 4/10でG0に呼び出せる。
なお、JIS X 0208-1983をG0に指示するにはESC 2/4 2/8 4/2となるはずだが、歴史的事情から終端文字が4/0〜4/2の場合はESC 2/4 <F>を使うという例外があり、実際はESC 2/4 4/2となる。これに対応するASCII文字で表示すると ESC $ B となる。
次に、実際に表示処理を行なうためには、バッファーに選び出された図形文字集合を7ビットの図形文字表に持ち込む必要がある。後述する8ビット符号では図形文字表はGL/TRの二つあるが、7ビット符号では一つしかないので、GL/GRの区別をする必要はない。
バッファーから呼び出すには、G0からはSI(0/15)、G1からはSO(0/14)、G2からは1/11 6/14、G3からは1/11 6/15を使用する。
実例として、G0にJIS X 0201ローマ字を、G1にJIS X 0201カナ(通称半角カナ)を指示したとする。ここでSIによってG0を呼び出すと、4/1 4/2 4/3はローマ字の "ABC" を、SOによってG1を呼び出すとカナの "アイウ" を意味することになる。
このようにして、SI/SOで両者を切り換えながら使うことが可能となる。
以上の拡張法は、1バイトのうち下位7ビットだけが使われるビット符号の拡張法で、ASCIIとの互換性と親和性が高い。一方、最上位ビットも使った8ビット符号の拡張法もある。
| 8ビット符号の利用法 |
8ビット符号拡張法は、7ビット符号と大差は無いが、図形文字表が左と右の二つある点が異なる。以降、左をGL、右をGRと呼ぶ。
8ビット符号 図解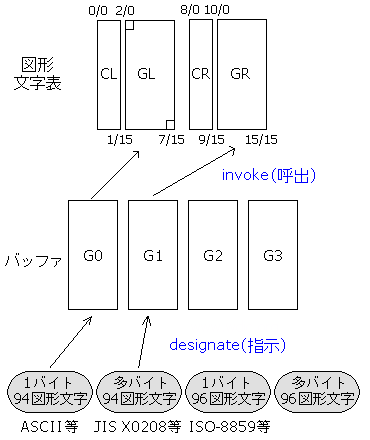
| 図形文字表とバッファー |
指示するためのシーケンスは、左の図形文字表に対しては7ビット符号の場合と全く同じである。そして右の図形文字表に指示するための符号が新たに用意される。
各バッファーから右の図形文字表(GR)に呼び出すには、G1からは1/11 7/14、G2からは1/11 7/13、G3からは1/11 7/12を使用する。G0を右の文字集合を割り当てることはできない。この制御文字は以後再び切り換えるまで効果が続くためLocking Shift(ロッキング・シフト)と呼ばれる。
8ビット符号拡張法では、左の図形文字表に呼び出された文字は7ビット符号と同様にそのままの符号で使用する。右の図形文字表に呼び出された文字を使うには符号の最上位ビットを1に変えて表わす。
| エスケープシーケンスの仕様 |
さて、こうすることでG0〜G3のバッファーのうち最大2バッファーを同時に利用することができるが、状況によっては3ないし4つ全てを利用したい場合も出てくる。
しかし例え1文字だけの場合でもいちいちエスケープで再呼び出しするのは冗長だし不便である。そこで、次の1文字だけをG2またはG3から呼び出す制御文字が用意されている。これは前述のLocking Shiftに対してSingle Shift(シングル・シフト)と呼ばれている。
具体的にはSS2(8/14)およびSS3(8/15)という機能文字を使うと、その次の1文字分だけ、右の図形文字表にG2やG3から呼び出すことができる。
| 8ビット範囲を7ビット互換条件で使う |
この8ビット符号の拡張法は1バイト中の8ビット全てを使う。8/0〜9/15の領域はC1領域と呼ばれ、0/0〜1/15のC0領域とは別の機能文字として使われる。
ところで上で述べたSS2(8/14)およびSS3(8/15)はC1領域の制御文字であるため、これでは7ビット符号で表現できない。そこで代用の方法を用いる。
7ビット符号でC1制御文字を表現するには、C1領域8/0〜9/15の代わりにエスケープシーケンス1/11 4/0〜5/15が使える。SS2/SS3は1/11 4/14と1/11 4/15で表現可能である。
| 8ビット実例 |
実例として、G1にJIS X 0208、G3にJIS X 0212補助漢字を指示し、G1をGRに呼び出したとする。ここでそのままGRを用いればJIS X 0208、SS3を使うと1文字のみGRがG3(JIS X 0212)となり、補助漢字をたまに用いつつ、普段はJIS X 0208として文書を作成できる。ちなみにこれはEUC-JPと呼ばれている方法でもある。
森鴎外の鴎を補助漢字にある正字で書く例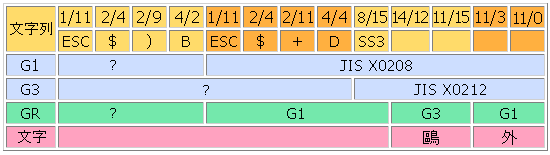
| エスケープシーケンス |
| エスケープの仕様 |
エスケープシーケンスは、ESC(1/11)に始まり、0字以上の中間バイトを挟み、終端バイトに終わる。従って長さはまちまちである。
中間バイトは2/0〜2/15の16種類であり、<I>で表わす。
終端バイトは3/0〜7/14の79種類であり、<F>で表わす。
中間バイト/終端バイト問わず、エスケープシーケンス中に0/0〜1/15と、7/15を含んではならない。また8ビット符号の場合、8/0〜15/15も含めてはならない。もし万一、これらを含むシーケンスを受け取った場合、処理系は何らかのエラー処理を要するだろうが、規格としてはその動作については未定義である。
「エスケープシーケンスの型」は、エスケープの直後に来る中間バイトによって決定される。中間バイトは16種類なので、エスケープシーケンスは16型あるといえる。
エスケープシーケンスの各バイトの意味は、この後に述べるように定義される。但し、エスケープシーケンスの意味は、個々のバイトに与えられた意味に関係なく、バイト列全体で規定される。
ESC(1/11)に続く文字は、2/0〜7/14である。
nFは、<I>、いわゆる「中間文字」で、その先頭バイトである。
Fp/Fe/Fsの第2バイトは終端バイト、つまり「終端文字」でもある。
nF型エスケープシーケンスは、制御機能を有する3F型を除き、各種の符号識別機能を表現するために用いられる。
終端文字Fに応じて、二つの副型に分けられる。
先頭の<I>の機能は、次の通りである。
| 型 | 先頭のIバイト | 2番目のIバイト | 機能 | ||
|---|---|---|---|---|---|
| 文字 | コード | 規則 | 用法 | ||
| 0F型 | 2/0 | N | ‐ | アナウンサ・コード・ストラクチャ | |
| 1F型 | ! | 2/1 | O | R | C0に終端文字<F>を指示する |
| 2F型 | " | 2/2 | O | R | C1に終端文字<F>を指示する |
| 3F型 | # | 2/3 | O | R | 単独制御機能 |
| 4F型 | $ | 2/4 | Y | R | 複数バイト図形文字集合(94n/96n) |
| 5F型 | % | 2/5 | O | R、S | ISO-2022以外の文字集合の指示 |
| 6F型 | & | 2/6 | N | ‐ | 改訂版の識別 |
| 7F型 | ' | 2/7 | N | ‐ | (将来の標準化のために保留) |
| 8F型 | ( | 2/8 | O | R、S | G0に終端文字<F>の94文字集合を指示する |
| 9F型 | ) | 2/9 | O | R、S | G1に終端文字<F>の94文字集合を指示する |
| 10F型 | * | 2/10 | O | R、S | G2に終端文字<F>の94文字集合を指示する |
| 11F型 | + | 2/11 | O | R、S | G3に終端文字<F>の94文字集合を指示する |
| 12F型 | , | 2/12 | N | ‐ | (将来の標準化のために保留) |
| 13F型 | - | 2/13 | O | R、S | G1に終端文字<F>の96文字集合を指示する |
| 14F型 | . | 2/14 | O | R、S | G2に終端文字<F>の96文字集合を指示する |
| 15F型 | / | 2/15 | O | R、S | G3に終端文字<F>の96文字集合を指示する |
それぞれ、「規則」に応じて継続するバイトを決める。
終端バイトがFpの場合の2番目(および後続)のIバイトは、規格では定義しない。
終端バイトがFtの場合、「規則」と「用法」の欄は、2番目(および後続)のIバイトに関連し、次のように規定される。
「規則」は次の通りとする。
「用法」は次の通りとする。
4F型のエスケープシーケンスの2番目の<I>バイトと、その機能は、次の通りである。
但し、<F>が4/0、4/1、または4/2の場合は、2番目の<I>バイトの2/8は使用しない。
複数バイト集合、つまり94n文字、96n文字の図形文字集合の大きさは、指示する際に使う終端バイト<F>によって決定される。
<F>の範囲は3/0〜7/14であり、次の通りとする。
動的再指定可能文字セット(DRCS)とは、いわゆる「ユーザー定義外字」のことである。視覚的外観をあらかじめ指定しておくことで、文字集合とする。
一度指定されると、DRCSは、適切なエスケープシーケンスでG0〜G3の符号要素として指示できる、文字集合のレパートリーの一つとしてみなされる。
DRCSの指示は、1バイトの図形文字表(GnDm機能、後述)では2番目の<I>バイトに、複数バイトの図形文字表(GnDMm機能、後述)では3番目の<I>バイトに、2/0を挿入することで行なう。
この場合、DRCS自体は、<F>バイト(存在するなら後続する<I>バイトも含めて)で識別する。<F>バイトは利用者が割り当て、情報交換当事者間の合意に基づいて利用する。
<F>バイトは、4/0から順番に割り当てて使うことが推奨されている。4/0〜7/14まで利用可能なため、94/94n、96/96n、おのおので63個までは、<I>バイトを使用しなくても<F>バイトだけで識別できる。
指示のエスケープシーケンスの使用例は次の通りである。
1バイトのものを総じてGnDm機能、複数バイトのものを総じてGnDMm機能という。
| 略号 | 文字集合 | 指示先 | エスケープ | |
|---|---|---|---|---|
| GZD4 | 1バイト94図形文字集合 | G0 | 1/11 2/8 <F> | ESC ( <F> |
| G1D4 | G1 | 1/11 2/9 <F> | ESC ) <F> | |
| G2D4 | G2 | 1/11 2/10 <F> | ESC * <F> | |
| G3D4 | G3 | 1/11 2/11 <F> | ESC + <F> | |
| G1D6 | 1バイト96図形文字集合 | G1 | 1/11 2/13 <F> | ESC - <F> |
| G2D6 | G2 | 1/11 2/14 <F> | ESC . <F> | |
| G3D6 | G3 | 1/11 2/15 <F> | ESC / <F> | |
| GZDM4 | 94n図形文字集合 | G0 | 1/11 2/4 2/8 <F> | ESC $ ( <F> |
| G1DM4 | G1 | 1/11 2/4 2/9 <F> | ESC $ ) <F> | |
| G2DM4 | G2 | 1/11 2/4 2/10 <F> | ESC $ * <F> | |
| G3DM4 | G3 | 1/11 2/4 2/11 <F> | ESC $ + <F> | |
| G1DM6 | 96n図形文字集合 | G1 | 1/11 2/4 2/13 <F> | ESC $ - <F> |
| G2DM6 | G2 | 1/11 2/4 2/14 <F> | ESC $ . <F> | |
| G3DM6 | G3 | 1/11 2/4 2/15 <F> | ESC $ / <F> | |
| 他の符号系 | 1/11 2/5(2/15)<F> | ESC ( <F> | ||
| アナウンス機能 |
| 手順 |
ISO/IEC 2022で文字を使う時の、最も基本的な使い方は、次のようになる。
指示は当該のエスケープシーケンスで行ない、呼出は基本的にはロッキングシフトで行なうことになる。
しかし、この手順は面倒であるため、それを省略する手順が用意されている。
| 用例 |
具体的には、特定のバッファーを図形文字表に直結しておき、「指示しただけで自動的に呼び出され即使用できる」ようにする。
この目的のために「アナウンサ」と呼ばれる符号列を使用し、ESC 2/0 <F>という符号列で機能を指定する。
ISO/IEC 2022:1994(JIS X 0202:1998)では、途中に抜けはあるが4/0〜5/12まで、多彩な利用方法が規定されている。
| 省略も可能 |
情報交換当事者間の合意があれば、アナウンサさえも省略してよいことになっている。
例えば、ISO-2022-JPなどでは、初期状態としてG0にASCII、さらに1/11 2/0 4/1というアナウンサが先行していると考え、情報交換当事者間の合意があったものとしてそれを略している。
| F=4/1 |
ISO-2022-JPで使用しているESC 2/0 4/1を例とする。
この場合、バッファーはG0しか使わないが、その代わりG0へ指示したものはすぐGL領域へ呼び出す。ロッキングシフトは使用しない。
また、8ビット符号では、GR領域は使用しない。
| 主要な符号 |
ISO/IEC 2022に準拠した、または非互換の独自拡張をした等の、主な符号系は次の通りである。言語ごとに分類する(順不同)。
| 終端文字一覧表 |
| 1バイト領域94図形文字集合 |
| 番号 | 図形文字集合 | 終端文字 | ASCII例 |
|---|---|---|---|
| 2 | ISO-646IRV:1983 | 4/0 | ESC ( @ |
| 4 | ISO-646-GB 英国 (BS 4730) | 4/1 | ESC ( A |
| 6 | ISO-646-US 米国 (ASCII) (X.3.4-1968) | 4/2 | ESC ( B |
| 8-1 | NATS-SEFI (フィンランド・スウェーデン) | 4/3 | ESC ( C |
| 8-2 | NATS-SEFI-ADD (フィンランド・スウェーデン) | 4/4 | ESC ( D |
| 9-1 | NATS-DANO (デンマーク・ノルウェー) | 4/5 | ESC ( E |
| 9-2 | NATS-DANO-ADD (デンマーク・ノルウェー) | 4/6 | ESC ( F |
| 10 | ISO-646-SE スウェーデン基本文字 | 4/7 | ESC ( G |
| 11 | ISO-646-SE2 スウェーデン名前文字 | 4/8 | ESC ( H |
| 13 | JIS X 0201片仮名 (通称半角カナ) | 4/9 | ESC ( I |
| 14 | JIS X 0201ローマ字 | 4/10 | ESC ( J |
| 21 | ISO-646-DE ドイツ(DIN 66 003) | 4/11 | ESC ( K |
| 16 | ISO-646-PT ポルトガル(ECMA, 1976) | 4/12 | ESC ( L |
| 39 | アフリカ語文字集合(DIN 31625, ISO 6438) | 4/13 | ESC ( M |
| 37 | 基本キリル文字集合(ECMA, ISO 5427:1981) | 4/14 | ESC ( N |
| 38 | 書誌用拡張図形文字集合(DIN 31624) | 4/15 | ESC ( O |
| 53 | 書誌用拡張図形文字集合(ISO 5426) | 5/0 | ESC ( P |
| 54 | 拡張キリル文字集合(ISO 5427:1981) | 5/1 | ESC ( Q |
| 25 | ISO-646-FR フランス(NF Z 62-010-1973) [廃止] | 5/2 | ESC ( R |
| 55 | 書誌用ギリシャ文字集合(ISO 5428-1980) | 5/3 | ESC ( S |
| 57 | ISO-646-CN 支那ローマ文字(GB 1988-80) | 5/4 | ESC ( T |
| 27 | ラテン・ギリシャ文字集合(ECMA) | 5/5 | ESC ( U |
| 47 | ビューデータ テレテクスト英国 | 5/6 | ESC ( V |
| 49 | INIS IRV サブセット | 5/7 | ESC ( W |
| 31 | 書誌用ギリシャ文字集合(ISO 5428-1974) | 5/8 | ESC ( X |
| 15 | ISO-646-IT イタリア(ECMA) (UNI 0204-70) | 5/9 | ESC ( Y |
| 17 | ISO-646-ES スペイン(ECMA) | 5/10 | ESC ( Z |
| 18 | ギリシャ文字集合(ECMA) | 5/11 | ESC ( [ |
| 19 | ラテン・ギリシャ文字集合(ECMA) | 5/12 | ESC ( \ |
| 50 | INIS 非標準拡張 | 5/13 | ESC ( ] |
| 51 | INIS キリル拡張 | 5/14 | ESC ( ^ |
| 59 | アラビア文字集合(CODAR-U) | 5/15 | ESC ( _ |
| 60 | ISO-646-NO ノルウェー(NS 4551 Version 1) | 6/0 | ESC ( ` |
| 61 | ISO-646-NO2 ノルウェー (NS 4551 Version 2) [廃止] | 6/1 | ESC ( a |
| 70 | ビデオテックス追加集合(CCITT) | 6/2 | ESC ( b |
| 71 | ビデオテックス Mosaic 第2追加(CCITT) | 6/3 | ESC ( c |
| 72 | ビデオテックス Mosaic 第3追加(CCITT) | 6/4 | ESC ( d |
| 68 | APL文字集合 | 6/5 | ESC ( e |
| 69 | ISO-646-FR フランス(NF Z 62-010-1982) | 6/6 | ESC ( f |
| 84 | ISO-646-PT ポルトガル(ECMA, 1984) | 6/7 | ESC ( g |
| 85 | ISO-646-ES2 スペイン(ECMA) | 6/8 | ESC ( h |
| 86 | ISO-646-HU ハンガリー(MSZ 7795/3) | 6/9 | ESC ( i |
| 88 | ギリシャ文字集合(ELOT) [廃止] | 6/10 | ESC ( j |
| 89 | アラビア(ASMO 449,ISO 9036) | 6/11 | ESC ( k |
| 90 | ISO 6937/2 補助集合 | 6/12 | ESC ( l |
| 91 | OCR-A図形文字集合(JIS C 6229:1984) [廃止] | 6/13 | ESC ( m |
| 92 | OCR-B図形文字(JIS C 6229 OCR-B) [廃止] | 6/14 | ESC ( n |
| 93 | OCR-B追加図形文字集合(JIS C 6229) [廃止] | 6/15 | ESC ( o |
| 94 | OCR用基本手書き図形文字集合(JIS C 6229) [廃止] | 7/0 | ESC ( p |
| 95 | OCR用追加手書き図形文字集合(JIS C 6229) [廃止] | 7/1 | ESC ( q |
| 96 | OCR用片仮名手書き図形文字集合(JIS C 6229)[廃止] | 7/2 | ESC ( r |
| 98 | E13B 図形文字集合(ISO 2033-1983) | 7/3 | ESC ( s |
| 99 | ビデオテックス・テレテクスト [廃止] | 7/4 | ESC ( t |
| 102 | T.61 テレテクスト基本図形文字集合 | 7/5 | ESC ( u |
| 103 | T.61 テレテクスト追加図形文字集合 | 7/6 | ESC ( v |
| 121 | ISO-646-CA カナダ図形集合 No.1(CSA Z 243.4-1985) | 7/7 | ESC ( w |
| 122 | ISO-646-CA2 カナダ図形集合 No.2(CSA Z 243.4-1985) | 7/8 | ESC ( x |
| 137 | T.101 データ構文 I Mosaic 1 集合 | 7/9 | ESC ( y |
| 141 | ISO-646-YU セルボクロアチア・スベロニアラテン文字 | 7/10 | ESC ( z |
| 146 | セルボクロアチアキリル文字(JUS I.B1.003) | 7/11 | ESC ( { |
| 128 | T.101 データ構文 III 追加文字集合 | 7/12 | ESC ( | |
| 147 | マケドニアキリル文字(JUS I.B1.004) | 7/13 | ESC ( } |
| 1バイト領域 第2中間文字2/1の94図形文字集合 |
| 番号 | 図形文字集合 | 終端文字 | ASCII例 |
|---|---|---|---|
| 150 | CCITT ギリシャ基本集合 | 4/0 | ESC ( ! @ |
| 151 | ISO-646-CU キューバ文字集合(NC 99-10:81) | 4/1 | ESC ( ! A |
| 170 | ISO/IEC 646-1992 invariant 文字集合 | 4/2 | ESC ( ! B |
| 207 | アイルランド・ゲール語 (I.S. 433:1996) | 4/3 | ESC ( ! C |
| 230 | トルコ語アルファベット (TDS 565) | 4/4 | ESC ( ! D |
| 231 | ANSI/NISO Z39.47 (ANSEL) | 4/5 | ESC ( ! E |
| 232 | トルコ語アルファベット (TDS 616-2003) | 4/6 | ESC ( ! F |
| 1バイト領域 96図形文字集合 |
| 番号 | 図形文字集合 | 終端文字 | ASCII例 |
|---|---|---|---|
| 111 | ECMA-94 ラテン/キリルアルファベット右部分 | 4/0 | ESC - @ |
| 100 | ISO-8859-1:1987 Latin alphabet No.1 右部分 | 4/1 | ESC - A |
| 101 | ISO-8859-2:1987 Latin alphabet No.2 右部分 | 4/2 | ESC - B |
| 109 | ISO-8859-3:1988 Latin alphabet No.3 右部分 | 4/3 | ESC - C |
| 110 | ISO-8859-4:1988 Latin alphabet No.4 右部分 | 4/4 | ESC - D |
| 123 | カナダ標準 Z 243.4一般用補助図形文字 | 4/5 | ESC - E |
| 126 | ISO-8859-7:1987 Latin/Greek alphabet(ECMA-118) | 4/6 | ESC - F |
| 127 | ISO-8859-6:1987 Latin/Arabic alphabet | 4/7 | ESC - G |
| 138 | ISO-8859-8:1988 Latin/Hebrew alphabet | 4/8 | ESC - H |
| 139 | チェコ標準 〓SN 36 91 03 右部分 | 4/9 | ESC - I |
| 142 | 追加図形文字集合(ISO 6937/2 plus Addendum 1) | 4/10 | ESC - J |
| 143 | 技術用集合 | 4/11 | ESC - K |
| 144 | ISO-8859-5:1988 Latin/Cyrillic alphabet | 4/12 | ESC - L |
| 148 | ISO-8859-9:1989 Latin alphabet No.5 右部分 | 4/13 | ESC - M |
| 152 | ISO 6937-2:1983 残余文字 | 4/14 | ESC - N |
| 153 | 8ビット基本キリル文字集合(ST SEV 358-88) | 4/15 | ESC - O |
| 154 | ラテンアルファベット No.1,2,5 追加集合 | 5/0 | ESC - P |
| 155 | 基本ボックス用集合 | 5/1 | ESC - Q |
| 156 | ISO/IEC 6937:1992 補助集合 | 5/2 | ESC - R |
| 164 | CCITT ヘブライ補助集合 | 5/3 | ESC - S |
| 166 | タイ語(TIS 620-2533 1990) | 5/4 | ESC - T |
| 167 | アラビア語/フランス語/ドイツ語文字集合 | 5/5 | ESC - U |
| 157 | ISO-8859-10:1992 Latin alphabet No.6 右部分 | 5/6 | ESC - V |
| 158 | ISO-8859-10:1992 Latin alphabet No.6 補助集合 | 5/8 | ESC - X |
| 179 | ISO-8859-13(ISO 4873) | 5/9 | ESC - Y |
| 180 | ベトナム語(TCVN 5712:1993, VSCII-2) | 5/10 | ESC - Z |
| 181 | 技術文字集合 No.1:IEC Publication 1289 | 5/11 | ESC - [ |
| 182 | ラテンアルファベットNo.1 Welsh 版 | 5/12 | ESC - \ |
| 197 | サーミ語 補助ラテン集合 | 5/13 | ESC - ] |
| 198 | Latin/Hebrew alphabet | 5/14 | ESC - ^ |
| 199 | ISO-8859-14 ケルト語補助ラテン文字集合 | 5/15 | ESC - _ |
| 200 | ウラル諸語 補助キリル文字集合 | 6/0 | ESC - ` |
| 201 | ヴォルガ川沿岸フィン諸語 補助キリル文字集合 | 6/1 | ESC - a |
| 203 | ISO-8859-15 補助ラテン文字集合 (Latin-9) | 6/2 | ESC - b |
| 204 | Latin-1補助集合 (ISO-8859-1+ユーロ通貨符号) | 6/3 | ESC - c |
| 205 | Latin-4補助集合 (ISO-8859-4+ユーロ通貨符号) | 6/4 | ESC - d |
| 206 | Latin-7補助集合 (ISO-8859-13+ユーロ通貨符号) | 6/5 | ESC - e |
| 226 | ISO-8859-16 情報交換用ルーマニア語文字集合 | 6/6 | ESC - f |
| 208 | 情報交換用オガム文字集合 | 6/7 | ESC - g |
| 209 | サーミ語 補助ラテン文字集合2 | 6/8 | ESC - h |
| 227 | ISO-8859-7:2003 Latin/Greek | 6/9 | ESC - i |
| 234 | ISO-8859-8:1999 Latin/Hebrew | 6/10 | ESC - j |
| 129 | CCITT Rec.T.101 データ構文III Mosaic 補助集合 | 7/13 | ESC - } |
| 複数バイト領域94×94図形文字集合 |
| 番号 | 図形文字集合 | 終端文字 | ASCII例 |
|---|---|---|---|
| 42 | 日本語漢字(JIS C 6226-1978)[廃止] | 4/0 | ESC $ @ |
| 58 | 支那語漢字(GB 2312-80) | 4/1 | ESC $ A |
| 87,168 | 日本語漢字(JIS X 0208-1990) | 4/2 | ESC $ B |
| 149 | 朝鮮語図形文字集合(KS X 1001) | 4/3 | ESC $ ( C |
| 159 | 日本語補助漢字集合(JIS X 0212-1990) | 4/4 | ESC $ ( D |
| 165 | CCITT 支那語漢字(ISO-IR-165) | 4/5 | ESC $ ( E |
| 169 | Blissymbol 図形文字集合 | 4/6 | ESC $ ( F |
| 171 | 台湾 正体字漢字(CNS 11643-1) | 4/7 | ESC $ ( G |
| 172 | 台湾 正体字漢字(CNS 11643-2) | 4/8 | ESC $ ( H |
| 183 | 台湾 正体字漢字(CNS 11643-3) | 4/9 | ESC $ ( I |
| 184 | 台湾 正体字漢字(CNS 11643-4) | 4/10 | ESC $ ( J |
| 185 | 台湾 正体字漢字(CNS 11643-5) | 4/11 | ESC $ ( K |
| 186 | 台湾 正体字漢字(CNS 11643-6) | 4/12 | ESC $ ( L |
| 187 | 台湾 正体字漢字(CNS 11643-7) | 4/13 | ESC $ ( M |
| 202 | 北朝鮮 情報交換用 標準朝鮮語図形文字集合 | 4/14 | ESC $ ( N |
| 228 | 日本語漢字(JIS X 0213:2000) 第一面 | 4/15 | ESC $ ( O |
| 229 | 日本語漢字(JIS X 0213:2000) 第二面 | 5/0 | ESC $ ( P |
| 233 | 日本語漢字(JIS X 0213:2004) 第一面 | 5/1 | ESC $ ( Q |
| 複数バイト領域96×96図形文字集合 |
現在は一つも定義されていない.
| 登録済みの他の符号系(ISO-2022 とは異なる他の符号系) |
エスケープシーケンスはESC 2/5 (2/15) <Ft>である。
なお、ESC 2/5 <Ft>の符号は、ESC 2/5 4/0で再びISO/IEC 2022に戻れることになっている(間に2/15を挟むものは戻らない)。
これは、ISO/IEC 2022のDOCS(DESIGNATE OTHER CODING SYSTEM)という他の符号化システムと併用するための機能の一つである。
| 番号 | 図形文字集合 | 終端文字 | ASCII例 |
|---|---|---|---|
| ISO/IEC 2022 | 4/0 | ESC % @ | |
| 108 | NAPLPS 構文(CSA T 500-1983) | 4/1 | ESC % A |
| 178 | UTF-1 | 4/2 | ESC % B |
| 131 | CCITT Rec.T.101 データ構文I | 4/3 | ESC % C |
| 145 | CCITT Rec.T.101 データ構文II | 4/4 | ESC % D |
| 160 | CCITT Rec.T.101 フォトビデオテックス | 4/5 | ESC % E |
| 161 | CCITT Rec.T.101 オーディオデータ構文 | 4/6 | ESC % F |
| 196 | UTF-8 | 4/7 | ESC % G |
| 188 | ITU-T Rec.T.107 VEMMI データ構文 | 4/8 | ESC % H |
| 162 | ISO/IEC 10646:1933,UCS-2,Level 1 | 2/15 4/0 | ESC % / @ |
| 163 | ISO/IEC 10646:1933,UCS-4,Level 1 | 2/15 4/1 | ESC % / A |
| 125 | Virtual Terminal service Transparent Set | 2/15 4/2 | ESC % / B |
| 174 | ISO/IEC 10646:1933,UCS-2,Level 2 | 2/15 4/3 | ESC % / C |
| 175 | ISO/IEC 10646:1933,UCS-4,Level 2 | 2/15 4/4 | ESC % / D |
| 176 | ISO/IEC 10646:1933,UCS-2,Level 3 | 2/15 4/5 | ESC % / E |
| 177 | ISO/IEC 10646:1933,UCS-4,Level 3 | 2/15 4/6 | ESC % / F |
| 190 | UTF-8 Level 1 | 2/15 4/7 | ESC % / G |
| 191 | UTF-8 Level 2 | 2/15 4/8 | ESC % / H |
| 192 | UTF-8 Level 3 | 2/15 4/9 | ESC % / I |
| 193 | UTF-16 Level 1 | 2/15 4/10 | ESC % / J |
| 194 | UTF-16 Level 2 | 2/15 4/11 | ESC % / K |
| 195 | UTF-16 Level 3 | 2/15 4/12 | ESC % / L |
| 版ごとの差異 |
これを著している時点では、この規格には総じて4種類の版がある。それぞれの特徴を下記する。
| ISO 2022:1973 |
最初の版である。
バッファーはG0とG1しかなく、94文字集合と94n文字集合しかなかった。
また、複数バイト文字集合はG0にしか指示できない。このため、ESC 2/4 <F>という3バイトのシーケンスで指示した。<F>は4/0、4/1、4/2までが割り当てられたが、以降の更新でG1以降にも指示可能になっても、互換性のためこの仕様は残された。
この頃、バッファーが二つしかなく、またそれらは符号表の今で言うGL/GRと一致していた。従って、この版ではGL、GRというものはなかった。つまり、C0、G0、C1、G1である。
94文字集合のみであったため、2/0は常にSP、7/15は常にDELであり、10/0と15/15は未定義である。
この頃のエスケープシーケンスは次の通りである。
| 符号列 | 用途 | |
|---|---|---|
| ESC 2/8 <F> | ESC ( <F> | 94文字集合をG0に指示し、呼び出す |
| ESC 2/12 <F> | ESC , <F> | |
| ESC 2/9 <F> | ESC ) <F> | 94文字集合をG1に指示し、呼び出す |
| ESC 2/13 <F> | ESC - <F> | |
| ESC 2/4 <F> | ESC $ <F> | 複数バイト文字集合をG0に指示し、呼び出す |
指示と呼び出しが二つあるのは、片方が尽きた時にもう片方を使うための予約だったと考えられる。
7ビット符号環境では、0/0から7/15の範囲内で用いる。
G0、G1はともに符号表の外部にあり、SI・SOという符号で呼び出して用いることになっていた。
SHIFT IN(0/15)でG0が呼び出され、SHIFT OUT(0/14)でG1が呼び出された。この名前からは、G0は内側(IN)のものであり、G1は外側(OUT)にあるものだ、という思想が見え隠れする。
| ISO 2022:1982 |
初の改定版であり、第二版と言える。
ここでバッファーとしてG2、G3が追加された。まだ96文字集合は存在しない。
複数バイト文字集合に対し、G1〜G3までに指示可能になった。
追加されたエスケープシーケンスは次の通りである。
| 符号列 | 用途 | |
|---|---|---|
| ESC 2/10 <F> | ESC * <F> | 94文字集合をG2に指示する |
| ESC 2/14 <F> | ESC . <F> | |
| ESC 2/11 <F> | ESC + <F> | 94文字集合をG3に指示する |
| ESC 2/15 <F> | ESC / <F> | |
| ESC 2/4 2/12<F> | ESC $ , <F> | 複数バイト文字集合をG0に指示する |
| ESC 2/4 2/9 <F> | ESC $ ) <F> | 複数バイト文字集合をG1に指示する |
| ESC 2/4 2/13 <F> | ESC $ - <F> | |
| ESC 2/4 2/10 <F> | ESC $ * <F> | 複数バイト文字集合をG2に指示する |
| ESC 2/4 2/14 <F> | ESC $ . <F> | |
| ESC 2/4 2/11 <F> | ESC $ + <F> | 複数バイト文字集合をG3に指示する |
| ESC 2/4 2/15 <F> | ESC $ / <F> | |
また、G2、G3を用いるため、呼び出し符号が多数新規に追加された。この版から、この規格は混迷を深め始めたといえる。
LS0Rは存在しないが、これはG0がGL(2/1〜7/14)と密接な結び付きがあることを意識したものと思われる。
| ISO 2022:1986 |
二回目の改定版であり、第三版と言える。
この版から、96文字集合が追加され、これに中間文字として2/13、2/14、2/15が充てられた。
この中間文字は、従来は94文字集合用の中間文字であったが、この仕様は廃止されたことになる。なお、ESC 2/4 2/12 <F>は削除された。
96文字集合導入に伴い、10/0と15/15が利用可能になった。
追加/変更されたエスケープシーケンスは次の通りである。
| 符号列 | 用途 | |
|---|---|---|
| ESC 2/13 <F> | ESC - <F> | 96文字集合をG1に指示する |
| ESC 2/14 <F> | ESC . <F> | 96文字集合をG2に指示する |
| ESC 2/15 <F> | ESC / <F> | 96文字集合をG3に指示する |
| ESC 2/4 2/8 <F> | ESC * ( <F> | 複数バイト文字集合をG0に指示する |
符号に統一性を持たせるためか、互換性はこのさい目をつむり、従来のESC 2/4 <F>に代えるESC 2/4 2/8というエスケープシーケンスが追加された。
しかしこの時点で、ESC 2/4 <F>の<F>には4/0、4/1、4/2の三つが追加されていたため、これはこのまま使用されることになった。
96文字集合はG1〜G3にのみ指示することができ、G0には指示出来ない。そのための中間文字がないからである。
この仕様からは、G0はGL(2/1〜7/14)である、という強い意識がここから読み取れる。つまり、G0〜G4というのは決して対等なものではないという考えがあると思われる。
しかし、7ビット符号で96文字集合を永続的に使うとなると、G1〜G3に指示したものをLS1〜LS3で2/0〜7/15に呼び出して使うことになる。そうなれば、どのみち聖域である2/0と7/15が潰れてしまうのは自明だろう。
そうであるなら、G0に96文字集合が指示出来てもおかしくないということになり、この件については様々な議論を巻き起こすことになった。
| ISO/IEC 2022:1994 |
三回目の改定版であり、第四版と言える。この版からISO/IEC 2022になり、規格書は全面的に刷新された。
Single Shift後の文字がGLでもGRでも良いことが明記された。もって、EUCでSS2/SS3の後でGRを使うことが問題なくなった。
ISO/IEC 4873を基にした実装水準が規定された。
ASN.1構文による表現が規定された。
登録済み集合に対する更新シーケンスが新たに規定された。これは、文字集合の改定ごとに新たな終端文字を作らずに済ませるための配慮である。
終端文字が変わると実装の変更も必要な上、貴重なリソースである終端文字の領域の残も減ってしまい、宜しくないことから、この結論に至ったと思われる。
例えば、JIS X 0208-1990とJIS X 0208-1983は終端文字が同じだが、1990が1983の改定版と見なされるよう、更新シーケンスとしてESC 2/6 4/0を付加することが必要となった。
| リンク |
| 通信用語の基礎知識検索システム WDIC Explorer Ver 7.04a (27-May-2022) Search System : Copyright © Mirai corporation Dictionary : Copyright © WDIC Creators club |